NIPS 2013
This year, NIPS (Neural Information Processing Systems) had a record registration of 1900+ (it has been growing over the years) with 25% acceptance rate. This year, most of the reviews and rebuttals are also available online. I was one of the many who were live tweeting via #NIPS2013 throughout the main meeting and workshops.
Compared to previous years, it seemed like there were less machine learning in the invited/keynote talks. Also I noticed more industrial engagements (Zuckerberg from facebook was here (also this), and so was the amazon drone) as well as increasing interest in neuroscience. My subjective list of trendy topics of the meeting are low-dimension, deep learning (and drop out), graphical model, theoretical neuroscience, computational neuroscience, big data, online learning, one-shot learning, calcium imaging. Next year, NIPS will be at Montreal, Canada.
I presented 3 papers in the main meeting (hence missed the first two days of poster session), and attended 2 workshops (High-Dimensional Statistical Inference in the Brain, Acquiring and analyzing the activity of large neural ensembles; Terry Sejnowski gave the first talk in both). Following are the talks/posters/papers that I found interesting as a computational neuroscientist / machine learning enthusiast.
Theoretical Neuroscience
Neural Reinforcement Learning (Posner lecture)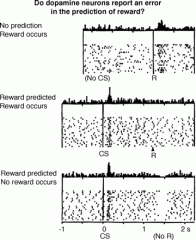
Peter Dayan
He described how theoretical quantities in reinforcement learning such as TD-error correlate with neuromodulators such as dopamine. Then he went on to Q (max) and SARSA (mean) learning rules. The third point of the talk was the difference between model-based vs model-free reinforcement learning. Model-based learning can use how the world (state) is organized and plan accordingly, while model-free learns values associated with each state. Human fMRI evidence shows an interesting mixture of model-based and model-free learning.
A Memory Frontier for Complex Synapses
Subhaneil Lahiri, Surya Ganguli
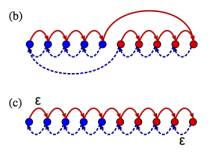
Despite its molecular complexity, most systems level neural models describe it as a scalar valued strength. Biophysical evidence suggests discrete states within the synapse and discrete levels of synaptic strength, which is troublesome because memory will be quickly overwritten for discrete/binary-valued synapses. Surya talked about how to maximize memory capacity (measured as area under the SNR over time) with synapses with hidden states over all possible Markovian models. Using the first-passage time, they ordered states, and derived an upper bound. Area is bounded by 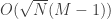
A theory of neural dimensionality, dynamics and measurement: the neuroscientist and the single neuron (workshop)
Surya Ganguli
Several recent studies showed low-dimensional state-space of trial-averaged population activities (e.g., Churchland et al. 2012, Mante et al 2013). Surya asks what would happen to the PCA analysis of neural trajectories if we record from 1 billion neurons? He defines the participation ratio 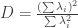
Distributions of high-dimensional network states as knowledge base for networks of spiking neurons in the brain (workshop)
Wolfgang Maass
In a series of papers (Büsing et al. 2011, Pecevski et al. 2011, Habenschuss et al. 2013), Maass showed how noisy spiking neural networks can perform probabilistic inferences via sampling. From Boltzmann machines (maximum entropy models) to constraint satisfaction problems (e.g. Sudoku), noisy SNN’s can be designed to sample from the posterior, and converges exponentially fast from any initial state. This is done by irreversible MCMC sampling of the neurons, and it can be generalized to continuous time and state space.
Epigenetics in Cortex (workshop)
Terry Sejnowski
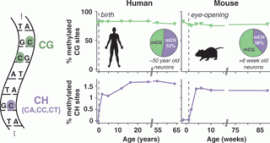
Using an animal model of schizophrenia using ketamine that shows similar decreased gamma-band activity in the prefrontal cortex, and decrease in PV+ inhibitory neurons, it is known that Aza and Zeb (DNA methylation inhibitors) prevents this effect of ketamine. Furthermore, in Lister 2013, they showed a special type of DNA methylation (mCH) in the brain grows over the lifespan, coincides with synaptogenesis, and regulates gene expressions.
Optimal Neural Population Codes for High-dimensional Stimulus Variables
Zhuo Wang, Alan Stocker, Daniel Lee
They extend previous year’s paper to high-dimensions.
Computational Neuroscience
What can slice physiology tell us about inferring functional connectivity from spikes? (workshop)
Ian Stevenson
Our ability to infer functional connectivity among neurons is limited by data. Using current-injection, he investigated exactly how much data is required for detecting synapses of various strength under the generalized linear model (GLM). He showed interesting scaling plots both in terms of (square root of) firing rate and (inverse) amplitude of the post-synaptic current.
Hierarchical Modular Optimization of Convolutional Networks Achieves Representations Similar to Macaque IT and Human Ventral Stream (main)
Mechanisms Underlying visual object recognition: Humans vs. Neurons vs. machines (tutorial)
Daniel L. Yamins*, Ha Hong*, Charles Cadieu, James J. DiCarlo
They built a model that can predict (average) activity of V4 and IT neurons in response to objects. Current computer vision methods do not perform well under high variability induced by transformation, rotation, and etc, while IT neuron response seems to be quite invariant to them. By optimizing a collection of convolutional deep networks with different hyperparameter (structural parameter) regimes and combining them, they showed that they can predict the average IT (and V4) responds reasonably well.
Least Informative Dimensions
Fabian Sinz, Anna Stockl, Jan Grewe, Jan Benda
Instead of maximizing mutual information between the features and target variable for dimensionality reduction, they propose to minimize the dependence between the non-feature space and the joint of target variable and feature space. As a dependence measure, they use HSIC (Hilbert-Schmidt independence criterion: squared distance between joint and the product of marginals embedded in the Hilbert space). The optimization problem is non-convex, and to determine the dimension of the feature space, a series of hypothesis testing is necessary.
Dimensionality, dynamics and (de)synchronisation in the auditory cortex (workshop)
Maneesh Sahani
Maneesh compared the underlying latent dynamical systems fit from synchronized state (drowsy/inattentive/urethane/ketamine/xylazine) and desyncrhonized state (awake/attentive/urethane+stimulus/fentany/medtomidine/midazolam). From the population response, he fit a 4 dimensional linear dynamical system, then transformed the dynamics matrix into a “true Schur form” such that 2 pairs of 2D dynamics could be visualized. He showed that the dynamics fit from either state were actually very similar.
Sparse nonnegative deconvolution for compressive calcium imaging: algorithms and phase transitions (main)
Extracting information from calcium imaging data (workshop)
Eftychios A. Pnevmatikakis, Liam Paninski
Eftychios have been developing various methods to infer spike trains from calcium image movies. He showed a compressive sensing framework for spiking activity can be inferred. A plausible implementation can use a digital micromirror device that can produce “random” binary patterns of pixels to project the activity.
Andreas Tolias (workshop talk)
Noise correlations in the brain are small (0.01 range; e.g., Renart et al. 2010). Anesthetized animals have higher firing rate and higher noise correlation (0.06 range). He showed how latent variable model (GPFA) can be used to decompose the noise correlation into that of the latent and the rest. Using 3D acousto-optical deflectors (AOD), he is observing 500 neurons simultaneously. He (and Dimitri Yatsenko) used latent-variable graphical lasso to enforce a sparse inverse covariance matrix, and found that the estimate is more accurate and very different from raw noise correlation estimates.
Whole-brain functional imaging and motor learning in the larval zebrafish (workshop)
Misha Ahrens
Using light-sheet microscopy, he imaged the calcium activity of 80,000 neurons simultaneously (~80% of all the neurons) at 1-2 Hz sampling frequency (Ahrens et al. 2013). From the big data while the fish was stimulated with visually, Jeremy Freeman and Misha analyzed the dynamics (with PCA) and orienting stimuli tuning, and make very cool 3D visualizations.
Normative models and identification of nonlinear neural representations (workshop)
Matthias Bethge
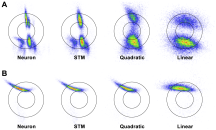
In the first half of his talk, Matthias talked about probabilistic models of natural images (Theis et al. 2012) which I didn’t understand very well. In the later half, he talked about an extension of the GQM (generalized quadratic model) called STM (spike-triggered mixture). The model is a GQM with quadratic term 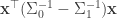

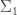
Inferring neural population dynamics from multiple partial recordings of the same neural circuit
Srini Turaga, Lars Buesing, Adam M. Packer, Henry Dalgleish, Noah Pettit, Michael Hausser, Jakob Macke
Under certain observability conditions, they stitch together partially overlapping neural recordings to recover the joint covariance matrix. We read this paper earlier in UT Austin computational neuroscience journal club.
Machine Learning
Estimating the Unseen: Improved Estimators for Entropy and other Properties
Paul Valiant, Gregory Valiant
Using “Poissonization” of the fingerprint (a.k.a. Zipf plot, count histogram, pattern, hist-hist, collision statistics, etc.), they find a simplest distribution such that the expected fingerprint is close to the observed fingerprint. This is done by first splitting the histogram into “easy” part (many observations; more than square root # of observations) and “hard” part, then applying two linear programs to the hard part to optimize the (scaled) distance and support. The algorithm “UNSEEN” has a free parameter that controls the error tolerance. Their theorem states that the total variations is bounded by 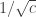
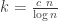
A simple example of Dirichlet process mixture inconsistency for the number of components
Jeffrey W. Miller, Matthew T. Harrison
They already showed that the number of clusters inferred from DP mixture model is inconsistent (at ICERM workshop 2012, and last year’s NIPS workshop). In this paper they show theoretical examples, one of which says: If the true distribution is a normal distribution, then the probability that # of components inferred by DPM (with 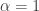
A Kernel Test for Three-Variable Interactions
Dino Sejdinovic, Arthur Gretton, Wicher Bergsma
To detect a 3-way interaction which has a ‘V’-structure, they made a kernelized version of the Lancaster interaction measure. Unfortunately, Lancaster interaction measure is incorrect for 4+ variables, and the correct version becomes very complicated very quickly.
B-test: A Non-parametric, Low Variance Kernel Two-sample Test
Wojciech Zaremba, Arthur Gretton, Matthew Blaschko
This work brings both test power and computational speed (Gretton et al. 2012) to MMD by using a blocked estimator, making it more practical.
Robust Spatial Filtering with Beta Divergence
Wojciech Samek, Duncan Blythe, Klaus-Robert Müller, Motoaki Kawanabe
Supervised dimensionality reduction technique. Connection between generalized eigenvalue problem and KL-divergence, generalization to beta-divergence to gain robustness to outlier in the data.
Optimizing Instructional Policies
Robert Lindsey, Michael Mozer, William J. Huggins, Harold Pashler
This paper presents a meta-active-learning problem where active learning is used to find the best policy to teach a system (e.g., human). This is related to curriculum learning, where examples are fed to the machine learning algorithm in a specially designed order (e.g., easy to hard). This gave me ideas to enhance Eleksius!
Reconciling priors” & “priors” without prejudice?
Remi Gribonval, Pierre Machart
This paper connects the Bayesian least squares (MMSE) estimation and MAP estimation under Gaussian likelihood. Their theorem shows that MMSE estimate with some prior is also a MAP estimate under some other prior (or equivalently, a regularized least squares).
There were many more interesting things, but I’m going to stop here! [EDIT: check out these blog posts by Paul Mineiro, hundalhh, Yisong Yue, Sebastien Bubeck, Davide Chicco]

Thanks Memming!