A guide to discrete entropy estimators
Shannon’s entropy is the fundamental building block of information theory – a theory of communication, compression, and randomness. Entropy has a very simple definition, 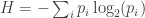


(click to enlarge)
Let me explain one by one. First of all, if you have continuous (analogue) observation, read the title of this post. CDM, PYM, DPM, NSB are Bayesian estimators, meaning that they have explicit probabilistic assumptions. Those estimators provide posterior distributions or credible intervals as well as point estimates of entropy. Note that the assumptions made by these estimators do not have to be valid to make them good entropy estimators. In fact, even if they are in the wrong class, these estimators are consistent, and often give reasonable answers even in the undersampled regime.
Nemenman-Shafee-Bialek (NSB) uses a mixture of Dirichlet prior to have an approximately uninformative implied prior on entropy. This reduces the bias of estimator significantly for the undersampled regime, because a priori, it could have any entropy.
Centered Dirichlet mixture (CDM) is a Bayesian estimator with a special prior designed for binary observations. It comes in two flavors depending if your observation is close to independent (DBer) or the total number of 1’s is a good summary statistic (DSyn).
Pitman-Yor mixture (PYM) and Dirichlet process mixture (DPM) are for infinite or unknown number of symbols. In many cases, natural data have a vast number of possible symbols, as in the case of species samples or language, and have power-law (or scale-free) distributions. Power-law tails can hide a lot of entropy in their tails, in which case PYM is recommended. If you expect an exponentially decaying tail probabilities when sorted, then DPM is appropriate. See my previous post for more.
Non-Bayesian estimators come in many different flavors:
Best upper bound (BUB) estimator is a bias correction method which bounds the maximum error in entropy estimation.
Coverage-adjusted estimator (CAE) uses the Good-Turing estimator for the “coverage” (1 – unobserved probability mass), and uses a Horvitz-Thompson estimator for entropy in combination.
James-Stein (JS) estimator regularizes entropy by estimating a mixture of uniform distribution and the empirical histogram with the James-Stein shrinkage. The main advantage of JS is that it also produces an estimate of the distribution.
Unseen estimator uses a Poissonization of fingerprint and linear programming to find the likely underlying fingerprint, and use the entropy as an estimate.
Other notable estimators include (1) a bias correction method by Panzeri & Travis (1995) which has been popular for a long time, (2) Grassberger estimator, and (3) asymptotic expansion of NSB that only works in extremely undersampled regime and is inconsistent [Nemenman 2011]. These methods are faster than the others, if you need speed.
There are many software packages available out there. Our estimators CDMentropy and PYMentropy are implemented for MATLAB with BSD license (by now you surely noticed that this is a shameless self-promotion!). For R, some of these estimators are implemented in a package called entropy (in CRAN; written by the authors of JS estimator). There’s also a python package called pyentropy. Targeting a more neuroscience specific audience, Spike Train Analysis Toolkit contains a few of estimators implemented in MATLAB/C.
References
- A. Antos and I. Kontoyiannis. Convergence properties of functional estimates for discrete distributions. Random Structures & Algorithms, 19(3-4):163–193, 2001.
- E. Archer*, I. M. Park*, and J. Pillow. Bayesian estimation of discrete entropy with mixtures of stick-breaking priors. In P. Bartlett, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 2024–2032. MIT Press, Cambridge, MA, 2012. [PYMentropy]
- E. Archer*, I. M. Park*, J. Pillow. Bayesian Entropy Estimation for Countable Discrete Distributions. arXiv:1302.0328, 2013. [PYMentropy]
- E. Archer, I. M. Park, and J. Pillow. Bayesian entropy estimation for binary spike train data using parametric prior knowledge. In C.J.C. Burges and L. Bottou and M. Welling and Z. Ghahramani and K.Q. Weinberger}, editors, Advances in Neural Information Processing Systems 26, 2013. [CDMentropy]
- A. Chao and T. Shen. Nonparametric estimation of Shannon’s index of diversity when there are unseen species in sample. Environmental and Ecological Statistics, 10(4):429–443, 2003. [CAE]
- P. Grassberger. Estimating the information content of symbol sequences and efficient codes. Information Theory, IEEE Transactions on, 35(3):669–675, 1989.
- J. Hausser and K. Strimmer. Entropy inference and the James-Stein estimator, with application to nonlinear gene association networks. The Journal of Machine Learning Research, 10:1469–1484, 2009. [JS]
- I. Nemenman. Coincidences and estimation of entropies of random variables with large cardinalities. Entropy, 13(12):2013–2023, 2011. [Asymptotic NSB]
- I. Nemenman, F. Shafee, and W. Bialek. Entropy and inference, revisited. In Advances in Neural Information Processing Systems 14, pages 471–478. MIT Press, Cambridge, MA, 2002. [NSB]
- I. Nemenman, W. Bialek, and R. Van Steveninck. Entropy and information in neural spike trains: Progress on the sampling problem. Physical Review E, 69(5):056111, 2004. [NSB]
- L. Paninski. Estimation of entropy and mutual information. Neural Computation, 15:1191–1253, 2003. [BUB]
- S. Panzeri and A. Treves. Analytical estimates of limited sampling biases in different information measures. Network: Computation in Neural Systems, 7:87–107, 1996.
- P. Valiant and G. Valiant. Estimating the Unseen: Improved Estimators for Entropy and other Properties. In Advances in Neural Information Processing Systems 26, pp. 2157-2165, 2013. [UNSEEN]
- V. Q. Vu, B. Yu, and R. E. Kass. Coverage-adjusted entropy estimation. Statistics in medicine, 26 (21):4039–4060, 2007. [CAE]

Hi Memming, I am really impressed by your efforts on putting together a nice chart for entropy estimation literature. We would like to share that recently we have proposed a new methodology for functional estimation (not only entropy estimation), and showed strong theoretical guarantees. Please refer to my answer http://math.stackexchange.com/questions/604654/estimating-the-entropy/936909#936909
for more details. 🙂
I would love a decently-documented single-file Java implementation of NSB. Best I’ve found is: https://gist.github.com/shhong/1021654/09fb0441f86250683561298581e69b85c9cccdc1 , which is python